Learning to Communicate in Multi-Agent Reinforcement Learning
Ever wondered if your Roomba is secretly plotting with your smart fridge?
While we might not be at that level of robotic scheming just yet, the question of how autonomous agents learn to communicate is a fascinating one. Imagine a team of robots navigating a warehouse or self-driving cars coordinating at an intersection—they need a way to talk to each other. But how do they figure out a language when no one gives them a dictionary? That’s what “Learning to Communicate with Deep Multi-Agent Reinforcement Learning” by Foerster et al. explores. Published in 2016, this paper is a classic in the field, emerging before the widespread adoption of attention mechanisms and transformers in multi-agent reinforcement learning.
1. Background: Why Learn Communication?
Traditional reinforcement learning (RL) assumes agents operate independently, optimizing their policies based only on individual observations and rewards. However, many real-world tasks require cooperation and information sharing. The challenge is that communication must be learned, not given.
“We investigate how agents can learn to communicate from scratch using deep reinforcement learning.”
This study explores centralized learning with decentralized execution, allowing agents to communicate freely during training but enforcing real-world communication constraints at test time.
The Problem of Learning to Communicate
Agents need to discover a shared communication protocol that encodes useful information. The challenge lies in the fact that both sending and interpreting messages must be learned simultaneously, making naive exploration ineffective. It’s like two people speaking completely different languages trying to coordinate a heist—chaos ensues until they develop a shared understanding.
2. What’s New Here?
The authors propose two approaches to tackle this challenge: Reinforced Inter-Agent Learning (RIAL) and Differentiable Inter-Agent Learning (DIAL).
RIAL: Reinforced Inter-Agent Learning
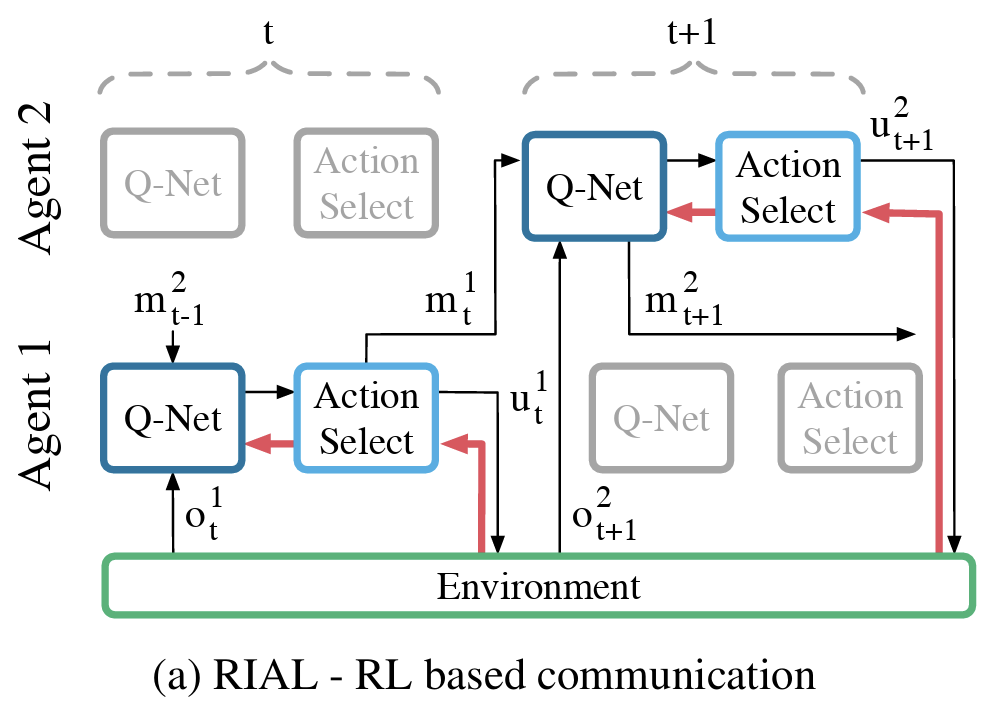
RIAL builds on Deep Q-Networks (DQN), a popular reinforcement learning approach, by integrating communication as part of the action space. Instead of treating messages as predefined symbols, agents must learn to send and interpret signals in a way that maximizes collective performance. Since learning effective communication from scratch is difficult, RIAL incorporates a deep recurrent Q-network (DRQN) to handle partial observability and improve long-term coordination.
To reduce the computational complexity of learning in a multi-agent setting, the authors decompose the Q-value estimation into two components: for environment actions and for communication actions**. Instead of maintaining a massive Q-table over both actions and messages, this separation allows more efficient training and better scalability.
Mathematically, each agent’s Q-network represents:
where is the agent’s observation, is the last received message, is the agent’s recurrent state, is the selected environment action, and is the message sent to other agents.
Although RIAL enables agents to learn communication strategies, it suffers from a fundamental limitation: messages are treated as discrete actions, which means gradients cannot flow directly from one agent to another. This restricts the optimization process, making it difficult for agents to converge on meaningful communication protocols efficiently. Unlike human communication, which is filled with fast feedback loops—such as nonverbal cues indicating understanding or confusion—RIAL lacks a mechanism for agents to provide direct feedback about their communication actions. As the paper states,
“While RIAL can share parameters among agents, it still does not take full advantage of centralized learning. In particular, the agents do not give each other feedback about their communication actions. Contrast this with human communication, which is rich with tight feedback loops.”
This absence of feedback makes learning a shared protocol significantly harder, as agents cannot refine their messaging based on responses, unlike how humans naturally adjust their speech based on real-time listener reactions.
DIAL: Differentiable Inter-Agent Learning
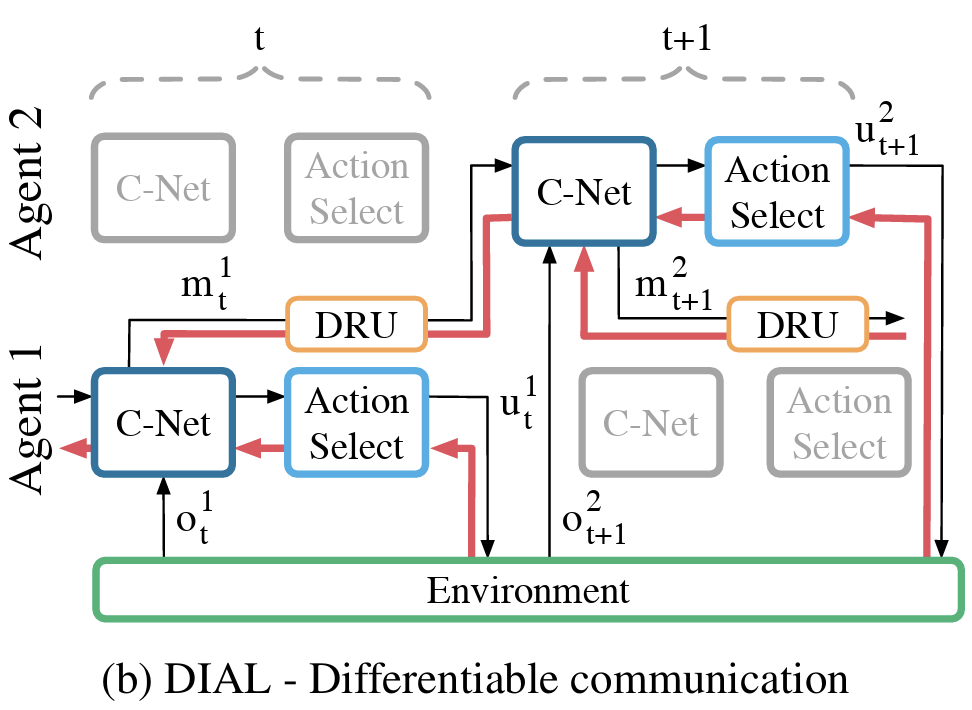
DIAL addresses the limitations of RIAL by allowing agents to communicate using differentiable message passing. Instead of treating messages as discrete actions, DIAL represents messages as continuous values during training, enabling gradient-based optimization across agents. This allows the learning process to directly influence communication, rather than relying purely on trial-and-error exploration.
One of the key innovations in DIAL is the Discretize-Regularize Unit (DRU), which converts continuous messages into discrete symbols for real-world execution while still allowing gradients to pass through during training. This mechanism ensures that agents can benefit from end-to-end optimization while still producing practical, deployable communication protocols.
Mathematically, the message at time step is computed as:
and gradients are propagated through the communication network via:
where is the communication network generating messages.
By enabling end-to-end differentiability, DIAL significantly improves the speed and efficiency of communication learning. Agents converge on effective protocols much faster than with RIAL, making DIAL a game-changer in multi-agent reinforcement learning.
3. Key Takeaways
This paper, published in 2016, remains a foundational work in learning-based communication for multi-agent systems. It predates modern transformer-based MARL approaches but introduced essential concepts that influenced later research. The key insights include:
- End-to-End Differentiability Matters: DIAL’s differentiable approach significantly accelerates learning compared to RIAL.
- Reducing Output Space Aids Learning: Decomposing the Q-value space into separate action and communication components makes learning more efficient.
- Noise Regularization Helps: Adding noise during training encourages more robust and discrete communication protocols.
- Gradient-Based Communication Learning is a Major Leap: By allowing gradients to flow across agents, DIAL enables faster and more effective protocol development.
These findings continue to shape research in multi-agent RL, robotics, and AI-driven coordination.
Final Thoughts
So, while your Roomba and smart fridge might not be gossiping just yet, the future of learned communication among autonomous agents is getting closer. Instead of hand-crafting protocols, we can now let AI figure it out on its own. The potential impact spans robotics, swarm intelligence, and autonomous multi-agent systems.
The next time you see two drones hovering a little too close to each other, just remember—they might just be learning a brand-new way to talk.
Disclaimer: The quotes and references above are adapted from “Learning to Communicate with Deep Multi-Agent Reinforcement Learning”.