Multiagent Bidirectionally-Coordinated Nets
In our journey through multi-agent communication research, we’ve seen how methods like RIAL/DIAL and CommNet began to tackle the coordination problem. Now, we turn to BiCNet (“Multiagent Bidirectionally-Coordinated Nets: Emergence of Human-level Coordination in Learning to Play StarCraft Combat Games,” Peng et al., 2017). This approach pushes the envelope by combining:
- Bidirectional Recurrent Communication among agents,
- A multi-agent actor-critic formulation for learning policies,
- Parameter sharing for scalability to larger, more complex tasks.
The result? Agents that can learn human-like coordination strategies—tested on the notoriously challenging StarCraft micromanagement scenarios.
1. From CommNet to BiCNet
Where CommNet Left Off
In CommNet, we saw how a continuous, broadcast-based approach to communication could accelerate learning and remain fairly modular. However:
- Communication was fully symmetrical (simple averaging of hidden states), which sometimes limited the model’s ability to handle heterogeneous agents or break ties among multiple actions.
- Scalability across very large groups of units (like StarCraft armies) demanded even more efficient messaging channels.
BiCNet’s Core Innovations
BiCNet addresses these points by using a bidirectional RNN to pass messages, providing a richer and more flexible communication structure. Each agent is one “module” in a bigger RNN chain, so the network learns to send and receive different messages in forward and backward passes. The approach:
- Differentiates communication roles more naturally (the forward pass vs. backward pass can encode distinct aspects of the group context).
- Simplifies handling heterogeneous agents by letting each agent type share parameters only with its own kind (e.g., ranged units share a network, melee units share a different one).
- Operates in an actor-critic manner, letting all agents learn continuous control policies with global or local rewards.
2. Core Idea: Bidirectional RNN + Multiagent Actor-Critic
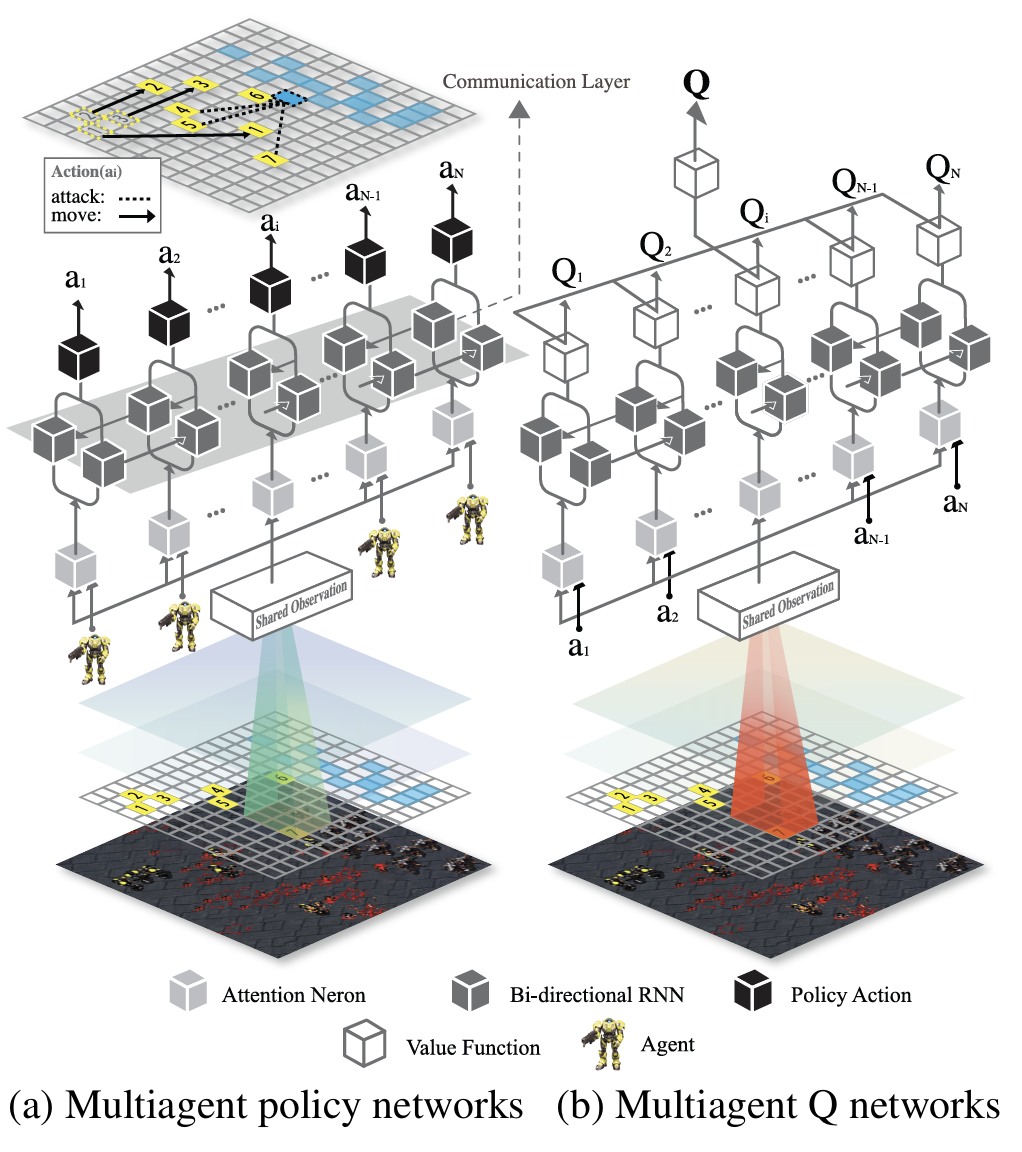
(Okay, confession time: When I first saw the BiCNet architecture five years ago, I was totally intimidated. It looked overwhelming! But trust me, it’s simpler than it looks.)
-
Parameter Sharing
Rather than give each agent a separate network, BiCNet shares parameters among agents of the same type. This lowers the overall parameter count (particularly helpful with large numbers of agents). -
Bidirectional Communication
Agents are laid out in a sequence (any order—often fixed by an ID or a spatial arrangement). A forward RNN passes messages from agent 1 to agent 2, to agent 3, …, while a backward RNN passes messages in the reverse direction. Each agent ends up with hidden states that incorporate context from both “sides.” -
Vectorized Actor-Critic Formulation
- Actor: Each agent outputs a (continuous) action, e.g., movement or firing angles.
- Critic: A Q-network (also with a bidirectional RNN) estimates the global or local action-value. Gradients from the critic help shape each agent’s policy.
- This approach can handle cooperative tasks, competitive tasks, or a combination (like in StarCraft micromanagement, where agents cooperate within a team but compete against an enemy team).
-
Scalable to Different Team Sizes
Because the architecture is essentially an RNN, adding or removing agents usually only changes the RNN’s sequence length—not the fundamental parameters. That makes it relatively easy to deploy on StarCraft battles with varied numbers of units.
3. How BiCNet Differs from DIAL/CommNet
-
Bidirectional Channels
- CommNet: Summation/averaging of hidden states → symmetrical broadcast.
- BiCNet: Each agent has a “forward message” and a “backward message,” which can be quite different. This asymmetry can help coordinate more nuanced tactics (e.g., “cover attacks,” as illustrated in the paper).
-
Actor-Critic vs. Q-Learning
- DIAL: Agents typically learn Q-values (like a DQN or a variant).
- CommNet: A feed-forward or recurrent net over the entire group, also Q-based or policy-based.
- BiCNet: Leans on deterministic policy gradients with a global critic (or local critics). Combined with continuous actions, it’s a more general solution for tasks with fine-grained movement or targeting angles.
-
StarCraft Combat as a Testbed
- RIAL/DIAL initially tested on simpler grid-world or matrix-based tasks.
- CommNet had toy tasks, predator-prey, and some simpler multi-robot domains.
- BiCNet focuses squarely on StarCraft micromanagement, one of the hardest multi-agent RL benchmarks due to partial observability, continuous time (approximated discretely), and a massive state-action space.
4. Key Takeaways & Results
-
Emergent Human-like Tactics
The BiCNet paper highlights advanced coordination patterns (e.g., “hit-and-run,” “focus fire without overkill,” “coordinated movement to avoid collisions”). The net discovered these purely from self-play and experience, with no human demonstrations. -
Adaptability
BiCNet can handle heterogeneous units (tanks, dropships, marines, etc.) by sharing parameters only among units of the same type. This allows seamless integration of different agent roles in the same environment. -
Scalability
By parameter sharing and the RNN-based architecture, BiCNet scales to larger teams, demonstrating success in scenarios like “15 Wraiths vs. 17 Wraiths” or “20 Marines vs. 30 Zerglings.” The performance consistently outperforms or matches existing baselines in StarCraft micromanagement tasks. -
One Model, Many Agents
As with CommNet, you don’t need to train a separate network for each possible team size. BiCNet’s recurrent structure allows a variable number of agents, making it more practical for real-world multi-agent systems or dynamic game scenarios.
5. Final Thoughts
BiCNet exemplifies a next generation approach to learned multi-agent communication and control:
- Richer than symmetrical broadcast methods,
- Scalable for large groups,
- Robust enough to handle complex tasks like StarCraft.
As research marches on, BiCNet remains an important milestone in bridging advanced RL with human-level teamwork—demonstrating how a carefully designed architecture (bidirectional RNN + multi-agent actor-critic + parameter sharing) can coax emergent strategies rivaling what human players do in real-time strategy games.
Further Reading
Disclaimer: Quotes and references adapted from “Multiagent Bidirectionally-Coordinated Nets: Emergence of Human-level Coordination in Learning to Play StarCraft Combat Games”